M2のニーです。今回はGANにおけるモード崩壊と呼ばれる問題点とそれを解決する手法について紹介します。
モード崩壊
モード崩壊とは、Generatorの学習が失敗し、出力する画像が非常に限られている現象です。
理想的には、生成ネットワークのサンプルは以下のように、二つのピークに集まり、学習データセットの分布と一致して欲しいです。
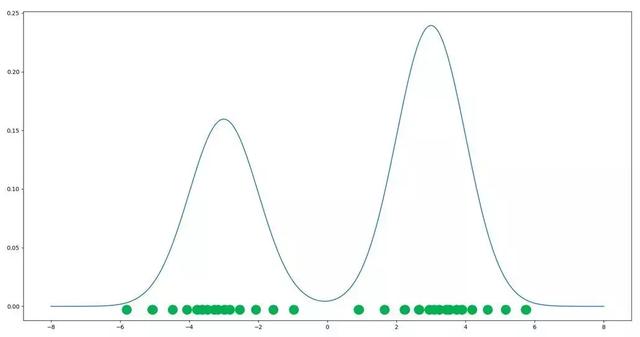
実際の生成画像はそこまで完璧できることはあまりなく、ピークのまわりに行ったり来たりして、すなわちちょっと怪しいな画像が作られるかもしれないですが、これはあくまで画像の品質の話です。モード崩壊が生じると、すべてのサンプルが一か所に集まり、大量なサンプルが類似してしまい、生成画像の多様性が失うということです。

モード崩壊を軽減するため、エントロピーの正則化、WGANに基づく改善など、たくさんの方法があるが、それらをまとめてみると、以下の四種類になります。
- 目的関数を変えてスコアを上げる
- 目的関数にパニッシュを加える
- 過学習を避ける
- より良い最適化方法を見つける
解決方法
今回はMinibatch DiscriminationとFeature Matchingという二つの対応策についてザクっと紹介します。
Feature Matching
Feature Matching はGeneratorの過学習を防ぐ新しい目的関数を作ることで、GANの不安定さに対処します。具体的には,GeneratorがDicriminatorの中間層の特徴量の期待値にマッチするように学習させる手法であり,以下のようにGeneratorの目的関数を定義します.
\($\min_G ||\mathbb{E}_{\boldsymbol{x} \sim p_{data}} \boldsymbol{f}(\boldsymbol{x}) - \mathbb{E}_{\boldsymbol{z} \sim p_{\boldsymbol{z}}(\boldsymbol{z})} \boldsymbol{f} (G(\boldsymbol{z}))||_2^2\)$
ただし,\(f(・)\)はDiscriminatorの中間層の出力を表します.その意味は生成されたものの特徴をなるべく本物に近づくようにすることです。元々Discriminatorは,本物か生成されたものかを最も判別可能な特徴量を見つけようとするので,この手法は自然な選択であると言えます。
オリジナルのGANのLossでは,データ分布と全く同じになる最適解が存在しましたが, Feature matching はGeneratorの損失関数に手を加えてしまうため,この最適解に達するかの保証はないです.しかし,[1]ではオリジナルでは不安定だったシチュエーションにおいて実験的に Feature matching は効果的であったと言っています。
Minibatch Discrimination
Discriminatorは画像の真偽を判断します。Generatorはそれを騙すためよりリアルな画像を作っていきます。
モード崩壊が生じる原因の一つは、Generatorが学習していくうちに、その出力である生成画像が互いに似ないように指示する機構が存在しないです。ミニバッチのサンプル間の近さをDiscriminatorに判別させることでこの問題を解決することができます.
具体的には、\(f(xi) \in \mathbb{R}^A\)をいま,Discriminatorの中間層にて生成される入力\(x_i\)の特徴量のベクトルとします.このベクトルをテンソル\(T \in \mathbb{R}^{A×B×C}\)で掛け,行列\(M_i \in \mathbb{R}^{B×C}\)を得たとします.
この方法では,\(M_i\)のL1距離をサンプルごとに取り,負号の指数乗を取ります.すなわちサンプル\(x_i\),\(x_j\)に対して,距離関数を \(c_b(x_i,x_j)=exp(−||M_{i,b}−M_{j,b}||_{L1}) \in \mathbb{R}\) と定めます.
これによって、ミニバッチ内の各サンプルの近さが測れます。
従来のように,Discriminatorは各データに対して,そのデータが本物である確率を表す数字を出力するようにします.Discriminatorのタスクは実質的に,そのデータが本物かどうかを識別することです.しかし,今ではサイド情報として,ミニバッチ内の他のサンプルを使うことができます.
まとめ
GANのモデルを訓練する時、モード崩壊はありがちの問題ですね。何時間も訓練して、最初のうちはいい感じですが、いつの間にか生成画像がほぼ同じになってしまうのはしんどいです。実際コードを書く時、モード崩壊が出ると、ハイパーパラメータ(入力\(z\)の次元数、バッチサイズなど)を調整するのが一番早いですが、今回はちょっと理論的な方法を紹介してみました。
Minibatch Discrimination はDiscriminatorにミニバッチ内のサンプルを比較する能力を与えました。一方、Feature MatchingはGeneratorの目的関数を変え、Dicriminatorの中間層の特徴とマッチするようにして、バッチの多様性を考慮しました。
今度モード崩壊があったら使ってみよう。
参考文献
- Improved Techniques for Training GANs.Tim Salimans,Ian Goodfellow. NIPS 2016
- Improved Techniques for Training GANs