M2の倪天佳です。今回はGauGANについて紹介したいと思います。
GauGAN: 落書きを風景写真に
今回紹介するのは、落書きをリアルな風景画にしてくれるAIツール「GauGAN」です。GauGANは敵対的生成ネットワーク(GAN)を用いて、落書きを写実的な画像に変化するモデルです。さらに、2021年にリリースされたGauGAN2により、セグメンテーションやテキストなどを併用し、より豊かな情報でより高品質な画像生成が可能になりました。
GauGAN2に至るまで
近年、GANに代表される画像生成技術が盛んできて、本物と見分けがつかないほど自然で高解像度の人の顔や動物の画像が生成できるようになりました。
これらのモデルで画像を生成する際に、人が干渉できるのは、カテゴリ指定、もしくは2枚の画像をミックスするなどに限られていました。しかし、実際の広告やメディア、アートのようなコンテンツ制作においては「自分がイメージした画像」が実際に生成できることが望ましいケースが多いです。
そのような研究としてはこれまでPix2Pix[1]が知られていました。
Pix2Pixも広い意味ではCGAN (Conditional GAN)の一種である。CGANでは「条件ベクトルと画像のペア」を学習データとしてその対応関係を学習していましたが、Pix2Pixでは「条件画像と画像のペア」を学習データとしてその対応関係を学習します。つまり、Pix2Pixは条件ベクトルの代わりに条件画像を使用し、画像から画像への変換問題を扱うCGANと言えます。
そのPix2Pixの改良バージョンPix2PixHDを用いたvideo-to-videoモデルが、2018年にNvidiaがリリースしたvid2vidのことでした。vid2vidで生成された動画は2048x1024の高解像度の動画です。

pix2pixHDと同じく、GauGANではセグメンテーションをリアルの画像に変換します。pix2pixHDに比べ、GauGANはより本物に近い画像が生成できるようになっています。pix2pixHDでは、たまに画像中の詳細な領域が表現できなくなったり、極端な場合、セマンティック情報が完全に損失することもあります。原因は恐らくnormalization layerにあると、詳細は論文の3節で説明されています。一方、GauGANではそういう損失がなく、より高品質の画像生成ができます。
GauGANの上でさらに一歩踏まえて、セグメンテーションだけじゃなく、テキストからも画像生成できるのが、つい最近のGauGAN2のことでした。

GauGAN2 Demoでのお試し
DauGAN2のDemoを試しにいじってみましょう。
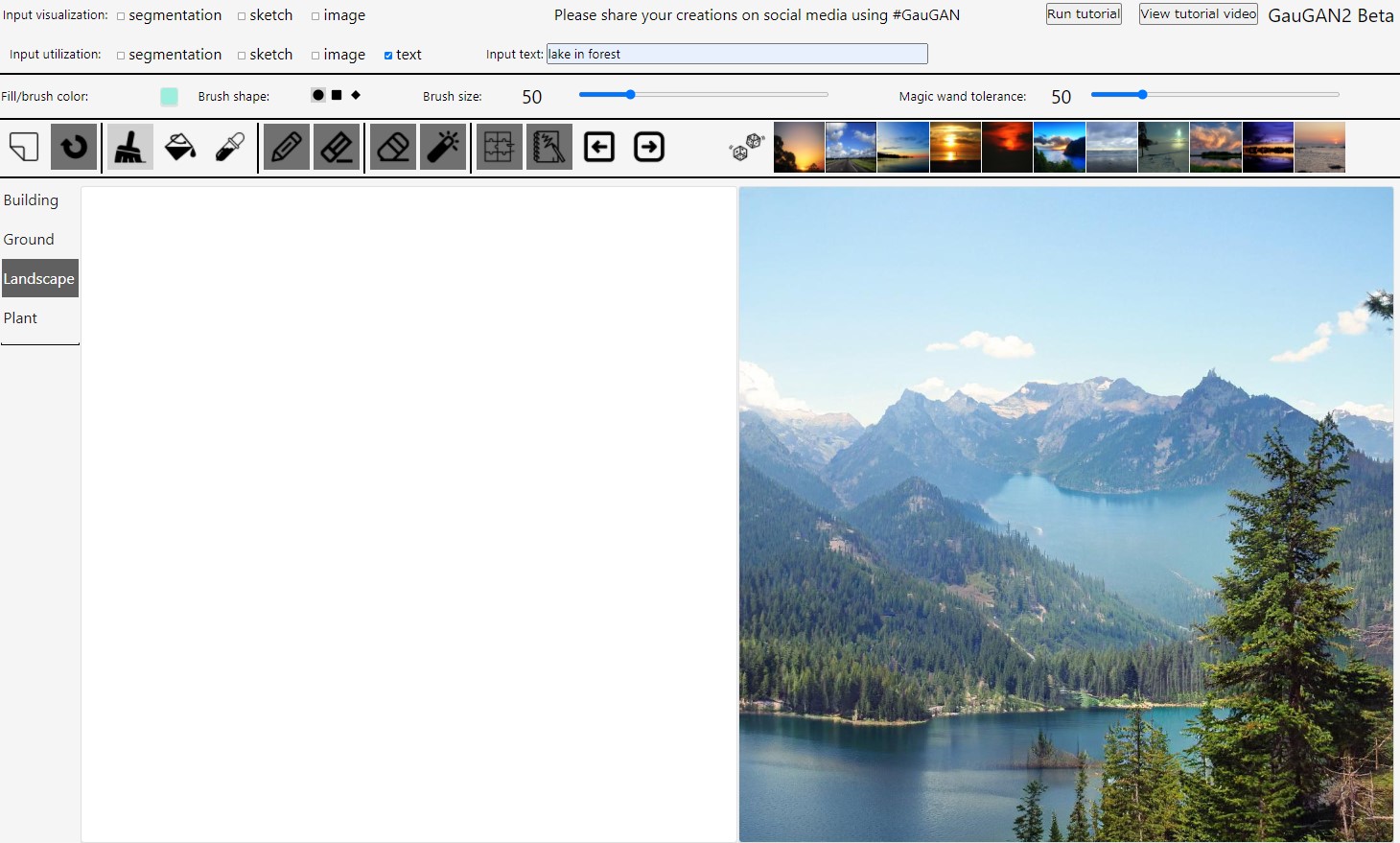
まず簡単なテキストだけを入れます。「lake in forest」「森の湖」を生成させた結果は図の通り。
ちょっと意地悪して、あまり現実的ではない画像を生成させてみよう。入力は「lake in the sky」「天空の湖」。

どうやら訓練データにない画像、つまりZero-shotの生成には弱いらしいです。DauGANの目標の一つは、簡単に画像を作れることにより、無駄な時間を減らし、アーティストをもっとクリエイティブな仕事に集中させることです。応用として、アニメや映画の背景などに使えそうですが、もしZero-shotに弱いとしたら、SFやファンタジーのような非現実的な画像生成が難しくなります。
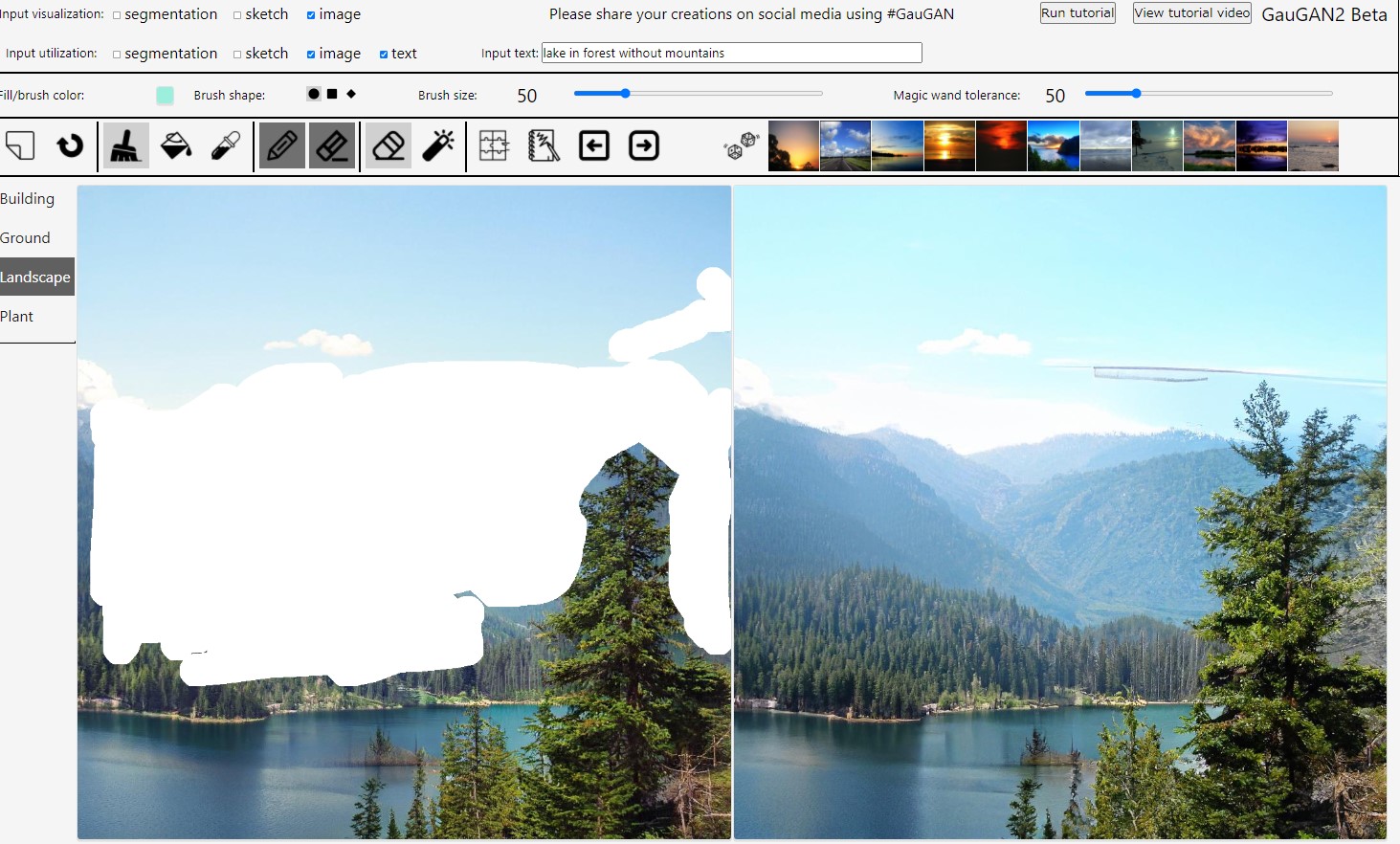
さらに、テキストで生成された画像をインターラクティヴで編集できます。例えば、最初に生成した「森の湖」という画像、背景の山が欲しくないなら、ブラッシュで山の部分を消して、さらにテキストで「without mountains」を指定します。生成画像は下の図。思い通りにはいかなかったらしいです。残念でした。
参考文献
- Phillip Isolaら. Pix2Pix. https://arxiv.org/abs/1611.07004
- Taesung Parkら. GauGAN. https://arxiv.org/abs/1903.07291